Paste Variables
To move data from a spreadsheet, text file, or other sources, Copy the table of data, go to Data Desk, and Paste. When the Clipboard contains text and the frontmost window is an icon window, the {Edit} Paste command says Paste Variables command. You do not need to create new variables first; Data Desk creates the variables you need. If the first row of your data table holds column names, Data Desk will offer these as variable names.
You will then see the Data Importing Dialog, where you can specify details.
Import Variables from a file
To open a text file that contains data, choose {File}Open. To Import data from a text file and add it to the data already on your Data Desk desktop, choose {File} Import. You will see the Data Importing Dialog where you can specify details about the data file and what to do with the variables imported.
Import Data Desk file
The {File} Import command will add the contents of an existing Data Desk saved file to the Data Desk desktop. It does not close the current file.
Open Data Desk file
The {File} Open command opens a Data Desk file. It will ask you to close a Data Desk file if you currently have one open.
Data Importing Dialog
When you import or paste text into Data Desk, you will see the data importing Dialog:
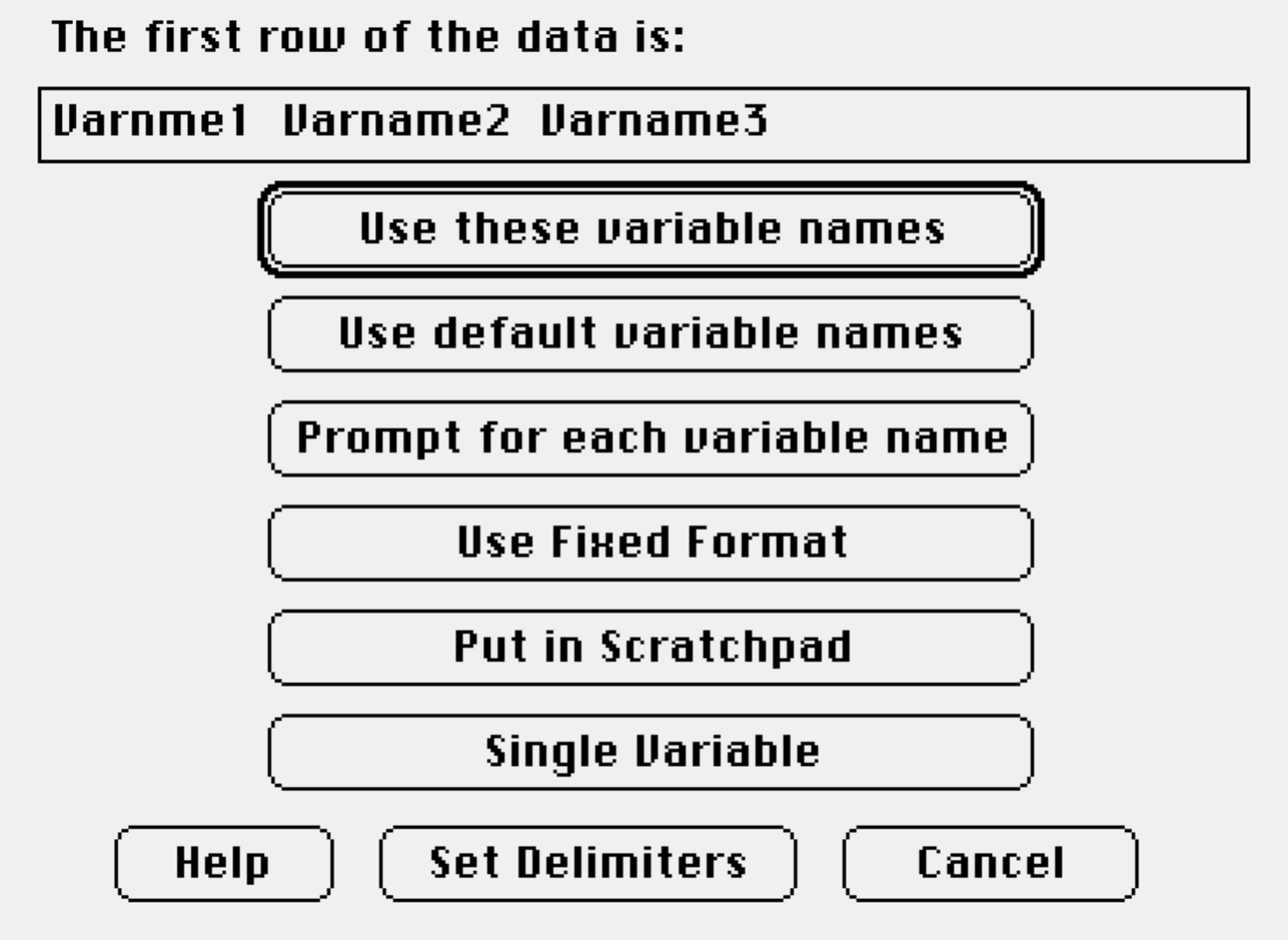
Click the “Use these variable names” button to accept the names displayed. Those are from the first row of the table being imported.
The default delimiter is the tab character. That is the character used, for example by most spreadsheet programs when you copy a table of data. Choose that button to specify alternative delimiters. (For example, a .csv file uses commas.)
Select Fixed Format if your data have no delimiting character between columns, but can be defined in terms of how many characters wide each column is.
Put your data in a Scratchpad if you think you’ll need to edit it further.
Put it in a single variable to use commands such as Split into Variables by Group, as may happen with data copied from some internet sites.
Generating Variables
Generate Random Numbers
The {Manip} Generate Random Numbers… command generates random samples from a selection of distribuitons.
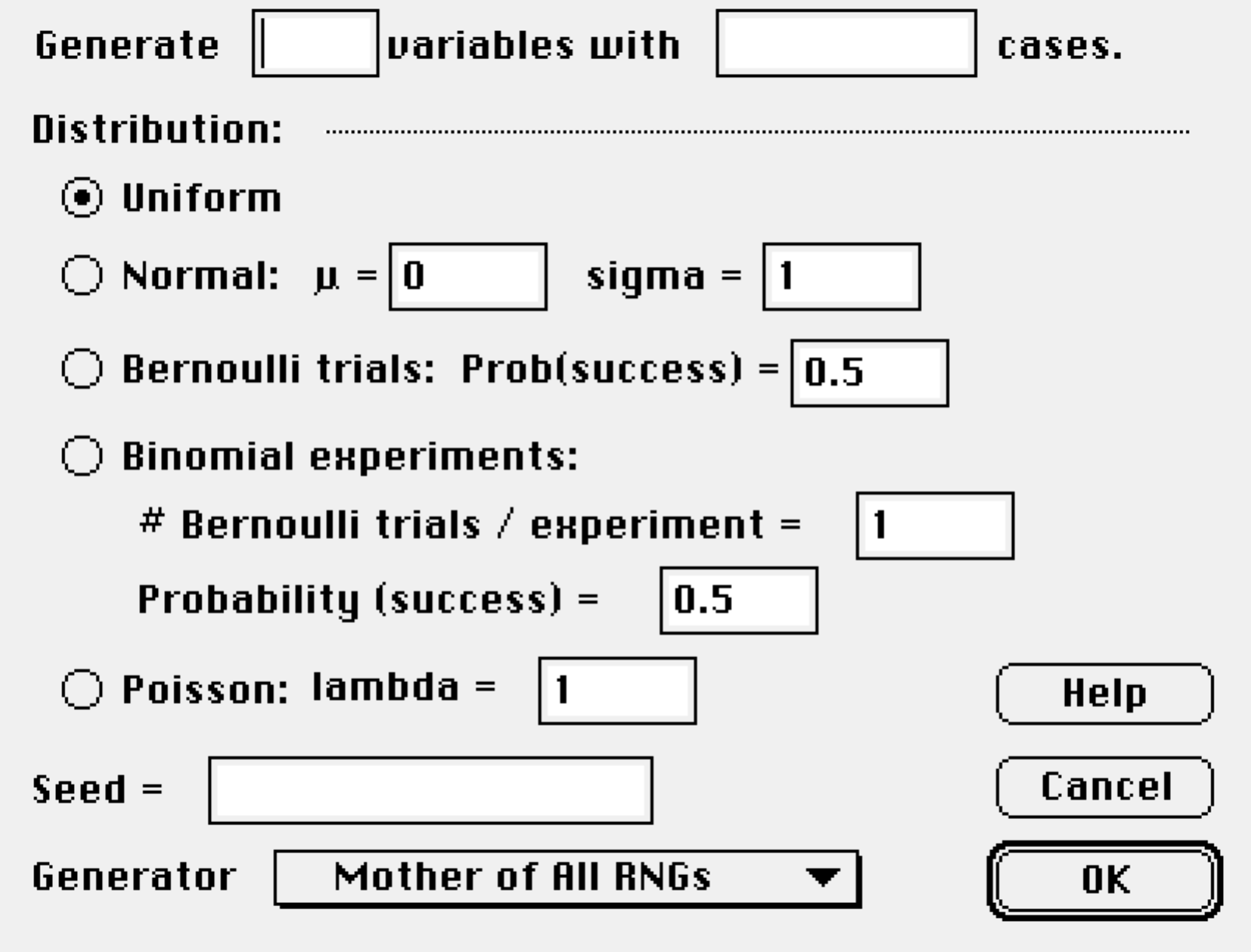
You can also select from three different pseudorandom number generators and specify a seed. With the same generator and the same seed, Data Desk will generate the same “random” values—a feature that can be useful for some simulation experiments.
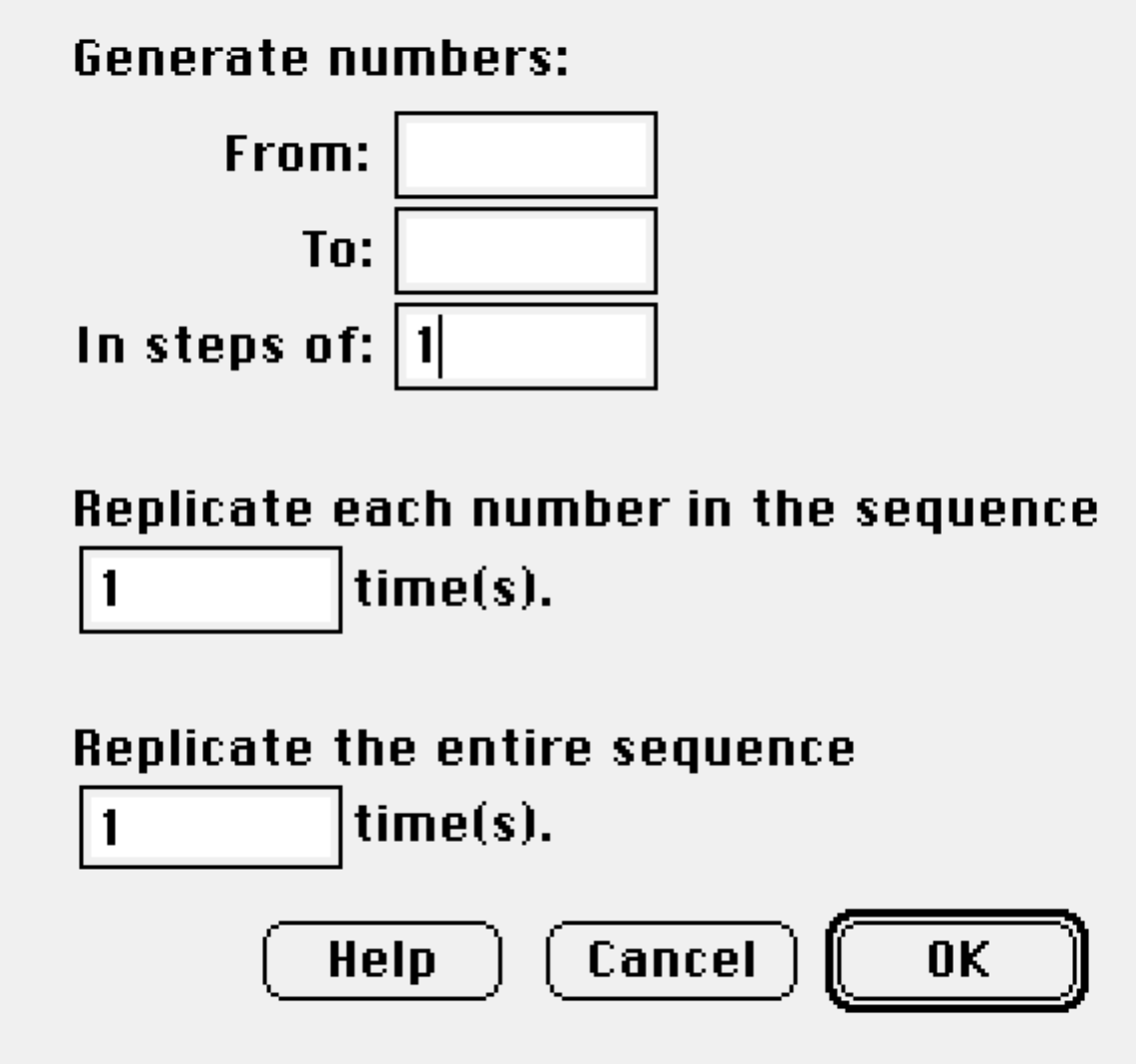
Generate Patterned Data
The {Manip}Generate Patterned Data command constructs a variable with values that follow a specified pattern.
Transform
The {Manip}Transform submenu offers a wide variety of way to manipulate and re-express variables. Select the variable(s) you wish to transform first (Selecting Variables), then choose a command from the submenus.
The most common data re-expression functions–square root, (base 10) Logarithm, reciprocal, and reciprocal root–appear first.
Functions are grouped into submenus by type:
- Arithmetic functions (sum, difference, etc)
- Exponentials (square, exp, etc)
- Logical (y < x, and other comparisons, y OR x, y AND x, etc.)
- Logical functions generate 1 for TRUE and 0 for FALSE
- Rounding (Absolute value, INT, RoundEven, etc.)
- Summary (Min, Max, sum, Mean, StdDev, etc.)
- Summary functions generate single values rather than new variables.
- Trigonometric functions
- Miscilaneous (Rank, Normal Scores, ZScores (standardize), Nest(y) (generates a unique instance of text in y), Concatonate (appends variables “horizontally”, and Cross (all combinations of categories in two variables))
- Dynamic: Each of these commands generates a Derived Variable and a Slider to control the parameter. Transfomed variables can be used in any plot or analysis and those can be set to update dynamically as the slider is moved. Box-Cox transformation is the usual family of powers and logs, Mix X and Y slides between all X and all Y through linear combinations of the two, Tukey’s Lambda is a family of re-expressions suitable for proportions or other values bounded by 0 and 1, and Lag shifts the data for use in time series anyses.
- Date and Time: These functions can extract parts of a date or time.
Repeat Variables
The {Manip}Repeat Variables command is used to construct structured variables. Select onr or more variables first then choose the command. One important use is to generate data from summarized counts to reproduce the original, un-summarized variables.
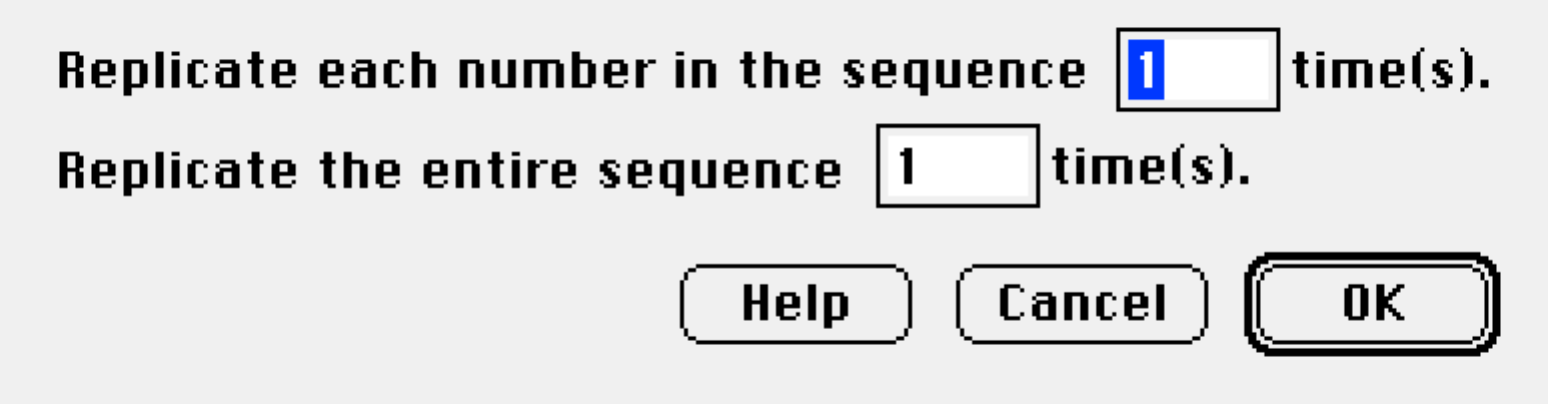
Replicate Y by X
The {Manip}Replicate Y by X command repeats each value in the Y variable the number of times specified in the X variable.
Append and Make Group Variable
The {Manip}Append and Make Group Variable command appends all selected variables end-to-end to make a single longer variable and generates a new Group variable that names the variable the cases came from.
Data recorded for groups can reside in a single variable with a second variable naming the groups or each group can reside in its own variable. Append and Make Group Variable takes the second format and turns it into the first one, whih is the form required by the Linear Model command. Split into Variables by Group changes the data structure in the opposite direction.
Split into Variables by Group
The {Manip} Split into Variables by Group command expects one or more variables selected as Y and a single categorical variable selected as X. It creates a new Relation for each group named in the X variable and places into each variables named as the Y variables were, but with only the cases for that group.
Transpose
Select any number of variables and choose {Manip}Transpose to treat the selected variables as columns of a matrix (in the order selected), transpose the matrix, and separate the new columns (the former rows) into variables.
Sample
The {Manip}Sample command provides ways to sample cases from the selected variables.
(see also) Data Editing
Data Size Limits
Data Desk has no practical limits on data size other than the physical constraints of your computer. Analyses with several millions of cases are quite practical on ordinary desktop computers. Large numbers of variables can be managed by grouping them into folders and then selecting or dragging (and dropping) the folders as a way of working with the variables within the folders.